Running qwen-2.5-coder:7B on macbook Air M2 using ollama
This is part of stay hungry stay folish mindset, and my interest in AI. Search possible solution to get cheapest code assistant as possible. i was subscribe to copilot but now after found continue.dev + anthropic API, thats the current choice.
Its small decrease in cost. copilot is $10 per month but now i am not that code heavy so subs to token based payment (anthropic claude 3.5 sonnet) is more cost effective. and pay base on what i use.
by the way, this blog is write by myself ya. :p
idea
Now in the search of the Cheapest one, my mind was :
wow if i could run llm locally and make continue.dev hitting the local llm, that will be good right?
it will be FREEEEEEEE

Model Search
ok, now when searching the newest model for coding, there is HOT model out there qwen-2.5-coder that just recently open sourced. thanks to Alibaba Cloud that develop and make it available to public.
so decided qwen-2.5-7b is the target model that i want to implement.
Tooling
when face with tooling, i already using ollama before and just use that. ollama is tooling to bridge llm to you. ollama is interface that will communicate with the llm.
start ollama by
ollama serve
and in another terminal start
ollama run qwen2.5-coder:7b
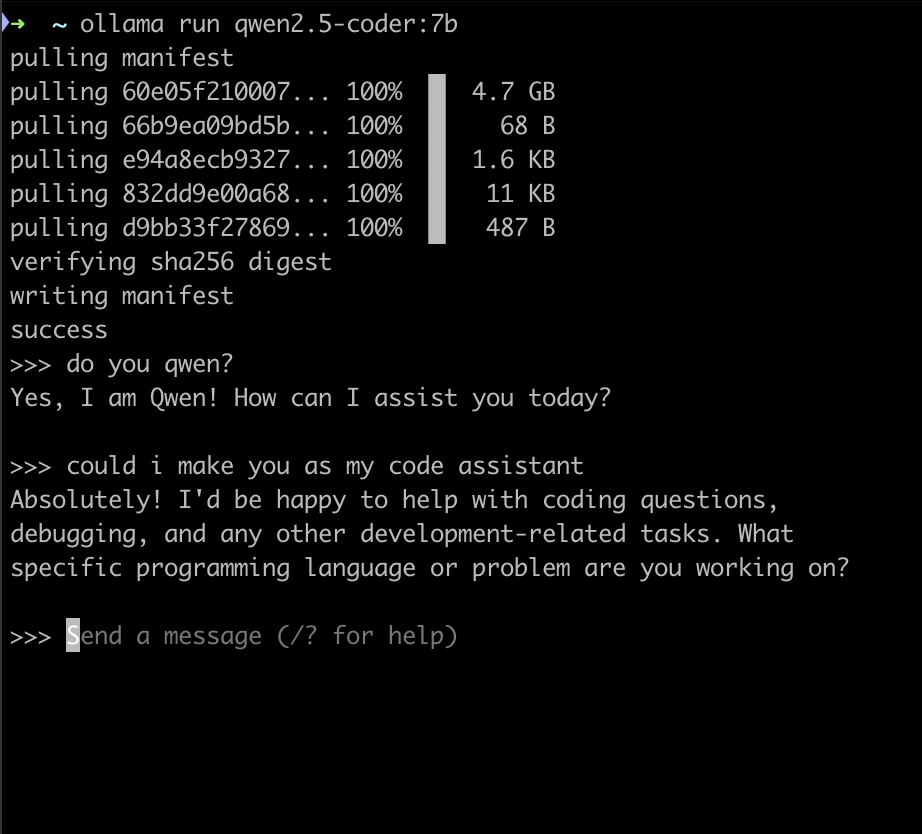
thats all thats an AI on your local or in this case is my M2 macbook air.
question and answer for general chat, pretty much the same. I am not bencmarking here, for generating simple code are oke. the next step is to make that as default model in continue.dev
integrate with continue.dev
from config on continue.dev in visualcode studio open the config with cmd+sift+p search for continue:config
{
"models": [
{
"model": "qwen2.5-coder:7b",
"provider": "ollama",
"title": "qwen2.5-coder-7b"
}
]
}
its working but Macbook M2 are freezing even the touchbar sometimes its freeze and cannot be clicked
and in this state i cancel all process to free the RAM
The Realization
- When running as chat in command line the llm are working fine. slow but still ok.
- When try in visualcode studio as code assistant its kind of freeze, work but extreamly slow.
- token based API + continue still the best and the most effective (for me).
summary step by step
- Install and Set Up Ollama
- Test the Model (ollama run {model})
- Integrate with Continue.dev
- enjoy and realize that how complex is LLM that even M2 is strugling.
thank you