Give PDF and talk about it
using lanchain to perform RAG using Ollama embedings and FAISS vectorstore
yeah maybe many tools already provide this kind of feature, But this is different, this is about knowing behind the scene. what actually they do to the pdf files? what actually we do to the text in it? and how the LLM is know what context they need?.
first thing first what is RAG? RAG is Retrieval Augmented Generation
RAG is like asking a person who doesn’t just rely on memory (llms default) but goes to check a book (pdf in this case) or notes before answering. First, it finds the right information (retrieval), then it uses that to give us a clear answer (generation). It’s smarter and targeted.
In this state we are gonna learn langchain that will get pdf files and we ask something about it and basically perform RAG. langchain_community is in awesome growth.
lets go:
LANGCHAIN PYTHON API REFERENCE
thats reference is make us easy to refer what the function or method is actually do.
this is the basic flow chart from what we are gonna build
what we are gonna do is 3 step.
1. Load pdf files and split to chunks
load the pdf file. since we are using langchain in the langchain_community there is pdfloader. and split the documents to chunks.
# Step 1: Load the PDF
def load_pdf(pdf_path):
loader = PyPDFLoader(pdf_path)
documents = loader.load()
return documents
# Split the text into chunks
def split_text(documents):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
return text_splitter.split_documents(documents)
2. do embedings -> vectorstores
we need to split the pdf text to chunks so it could translate our docs to vecrorstore. we could say its a data that could understand by the LLM’s. and because we not yet big lets use vectorestore FAISS using in memory. In python and in this AI world. everything is already wraped. but if you want to learn more FAISS here also there is a paper in it faiss paper
the embedding: since we use ollama we use OllamaEmbeddings there should be OpenAIEmbbedings, also full docs could read here ollama embedings
# Step 2: generate embeddings using OllamaEmbedings
def create_vectorstore(chunks):
embeddings = OllamaEmbeddings(model="mistral") #just use mistral its run on local btw
vectorstore = FAISS.from_documents(chunks, embeddings)
return vectorstore
we also could use another vectorstore but now we use FAISS
3. build the RAG chains
Build the RAG pipeline. honestly i am using AI to find this code cause reading this still strugling chain there is many chain and i am using the RetrievalQA
def build_rag(vectorstore):
retriever = vectorstore.as_retriever()
llm = OllamaLLM(model="mistral") # Specify Mistral model
qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever)
return qa_chain
Combine that together as Q&A system prompt.
# Combine all to main
def main():
pdf_path = "/Users/prima/Downloads/jefferey-ollama.pdf" # Path to your PDF file
documents = load_pdf(pdf_path)
chunks = split_text(documents)
vectorstore = create_vectorstore(chunks)
qa_chain = build_rag(vectorstore)
# Chat with the PDF
while True:
query = input("Ask a question about the document: ")
if query.lower() == "exit":
break
response = qa_chain.invoke(query)
print(f"Answer: {response}")
Result and Learnings
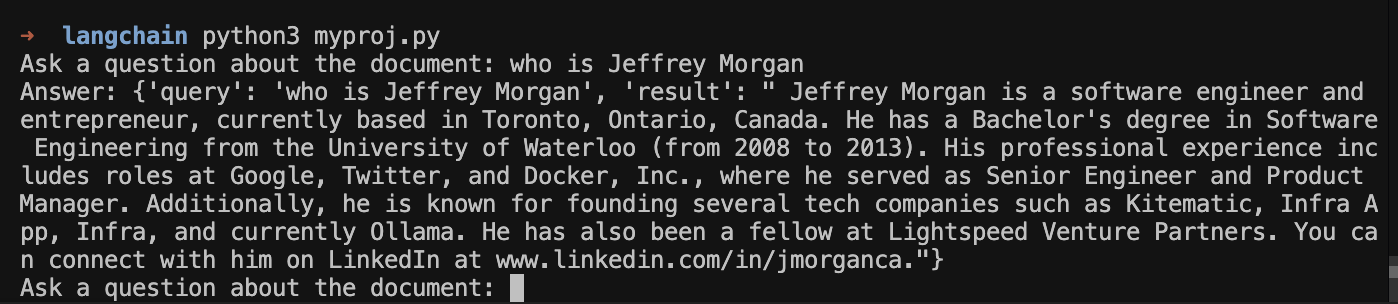
with this we are able to ask something about the pdf that we are give to the system. in this example i am creating pdf files base on Jeffrey Morgan linked in profile export pdf jeffrey Morgan.
chatgpt (not mentioning ollama) jeffrey morgan is:
jeffrey is an actor

olama mistral without pdf (clean mistral) not using RAG
jeffrey is an actor

when i ask our RAG ollama and ask about jefferey morgan the reult is success:
jeffrey is an engineer
this is the full code and enjoy
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_ollama import OllamaLLM, OllamaEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
# Step 1: Load the PDF
def load_pdf(pdf_path):
loader = PyPDFLoader(pdf_path)
documents = loader.load()
return documents
# Split the text into chunks
def split_text(documents):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
return text_splitter.split_documents(documents)
# Step 2: generate embeddings using OllamaEmbedings
def create_vectorstore(chunks):
embeddings = OllamaEmbeddings(model="mistral") #just use mistral its run on local btw
vectorstore = FAISS.from_documents(chunks, embeddings)
return vectorstore
# Step 3: Build the RAG system
def build_rag(vectorstore):
retriever = vectorstore.as_retriever()
llm = OllamaLLM(model="mistral") # Specify Mistral model
qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever)
return qa_chain
# Combine all to main
def main():
pdf_path = "/Users/prima/Downloads/jefferey-ollama.pdf" # Path to your PDF file
documents = load_pdf(pdf_path)
chunks = split_text(documents)
vectorstore = create_vectorstore(chunks)
qa_chain = build_rag(vectorstore)
# Chat with the PDF
while True:
query = input("Ask a question about the document: ")
if query.lower() == "exit":
break
response = qa_chain.invoke(query)
print(f"Answer: {response}")
if __name__ == "__main__":
main()
make sure have pip and python also install all requirements
langchain has move their community module to
langchain_communitysince they are have enterprise package and products.