Candidate discovery demo
In this post will be litle bit technical. continuing what i already created that talk with pdf (RAG).
combining this nextjs from bolt.new chat with ollama and langchain for talking with pdf files
we will slightly re-architec the app user flow design. before, we use FAISS to store our vector. i am afraid it cannot scale (do not know how to scale). so in search of vector databases. i encounter with bunch of option there is pgai (that really take my interest) still in beta, but also qdrant that already have their enterpise option.
lets use this stack then :
- qdrant vector database , why? is the most mature afaik and backed by a company
- using flask/fast api to serve (the auto swagger will be easy to build the frontend)
so the goal here is
- could upload a resume of candidate -> embed and save to qdrant
- could search -> (using RAG) best candidate with chat.
- return with human language
no need for overall docs here (like saving the original docs in rdbms (not chunked)), if doing it it could be expand to give more context to the models but now lets focus on the qdrant similarity first for now
graph and architecture
define step
- installing qdrant
- code the fast api add some logic
- POST pdf/text => embeding => qdrant => success/error
- POST {query_content:} => reult the match candidate (querystring for now is enough)
- POST for plain text candidate data (testing purpose)
no validation :p since its just a demo
qdrant docker install
lets do this 1 we need to install qdrant (docker is enough)
docker run -it -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
-d qdrant/qdrant
we could go to qdrant dashboard at localhost:6333/dashboard
The Code
in this code obviously started with open AI to create a baseline all endpoints and edit from that this code is base on 3 endpoints
- add new candidate (not really care about name for now and ignore filtering)
- add new candidate using pdf (upload) not working yet (same as above but from pdf)
- query candidate and answer it using openAI API
we use open AI API for embeding (turn text to vector) and using for chat completion for answering with human language.
from fastapi import FastAPI, File, UploadFile, HTTPException
from pydantic import BaseModel
import shutil
import logging
from openai import OpenAI
from openai.types import Completion, CompletionChoice, CompletionUsage
from qdrant_client import QdrantClient
from qdrant_client import models
from qdrant_client.http.models import Distance, VectorParams
from langchain_core.documents import Document
from langchain_community.document_loaders import PyPDFLoader
from langchain_qdrant import QdrantVectorStore
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from uuid import uuid4
#initiate fast api and logging (global config)
app = FastAPI()
logging.basicConfig(level=logging.INFO)
clientq = QdrantClient(url="http://localhost:6333")
openai_api_key = "use your open ai key"
# Initialize OpenAI Embeddings and Qdrant col name and openai client
embedding_model = OpenAIEmbeddings(api_key=openai_api_key)
clientopenai = OpenAI(
api_key=openai_api_key, # This is the default and can be omitted
)
collection_name = "demo_candidates"
# Check if the collection exists just create it when its `not` already exist
collections = clientq.get_collections()
existing_collections = [col.name for col in collections.collections]
# changes to "in" (for me to easy delete the collection or recreate)
if collection_name not in existing_collections:
clientq.delete_collection(collection_name)
clientq.create_collection(
collection_name="demo_candidates",
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
# Initialize Qdrant vector store
vectorstore = QdrantVectorStore(
client=clientq,
collection_name="demo_candidates",
embedding=embedding_model,
)
# Candidate model for json input request
class Candidate(BaseModel):
id: str
description: str
def load_pdf(pdf_path):
loader = PyPDFLoader(pdf_path)
documents = loader.load()
return documents
@app.post("/candidate")
async def add_candidate(candidate: Candidate):
try:
# Load and split the text
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_text(candidate.description)
# Wrap each chunk in a Document object with proper structure
documents = []
candidate_id = str(uuid4())
for chunk in chunks:
documents.append(Document(page_content=chunk, metadata={"source": "candidate", "candidate_id": candidate_id}))
# Add text chunks to Qdrant
vectorstore.add_documents(documents=documents)
logging.info(f"Added candidate: {candidate.id}")
return {"message": "Candidate added successfully"}
except Exception as e:
logging.error(f"Error adding candidate: {e}")
raise HTTPException(status_code=500, detail="Could not add candidate")
@app.post("/candidate/pdf")
async def add_candidate_pdf(file: UploadFile = File(...)):
try:
# save the uploaded PDF file to a temporary location
with open(f"temp/{file.filename}", "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
# load and split the text
documents = load_pdf(f"temp/{file.filename}")
# spliter better use RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
candidate_id = str(uuid4())
for chunk in chunks:
# this take a long time turns out chunk already have property page_content but i am not sure all have that so just to make sure
if isinstance(chunk, str):
page_content = chunk
elif isinstance(chunk, Document):
page_content = chunk.page_content
else:
raise ValueError("Chunk is not a valid string or Document object.")
documents.append(Document(page_content=page_content, metadata={"source": "candidate", "candidate_id": candidate_id}))
# Add text chunks to qdrant
vectorstore.add_documents(documents=documents)
logging.info(f"Uploaded and added file: {file.filename}")
return {"message": "Candidate PDF uploaded and embedded successfully"}
except Exception as e:
logging.error(f"Error processing file: {e}")
raise HTTPException(status_code=500, detail="Could not process the file")
@app.post("/candidate/query")
async def query_candidates(query: str):
try:
print(query)
# Perform similarity search in Qdrant
results = vectorstore.similarity_search(
query=query,
k=3,
)
# Extract matches
matches = [
{"id": result.metadata.get("candidate_id", "Unknown"), "text": result.page_content}
for result in results
]
# Format results for OpenAI
result_texts = "\n".join(
[f"Candidate ID: {match['id']}, Description: {match['text']}" for match in matches]
)
#conversationally is the best word
prompt = (
f"You are an expert HR assistant. A user asked: '{query}'. Based on the following "
f"candidate descriptions, respond conversationally:\n\n{result_texts}"
)
# Generate a human-like response using OpenAI
openai_response = clientopenai.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
print(openai_response.choices)
conversational_response = openai_response.choices[0].message.content
logging.info(f"Querying candidates with: {query}")
return {"response": conversational_response, "matches": matches}
except Exception as e:
logging.error(f"Error querying candidates: {e}")
raise HTTPException(status_code=500, detail="Could not query candidates")
we could coppy that code and make open AI explain it but i already explain some of the important part on the comment.
after that just open localhost:8000 (default port for fast api) and this is already the swagger of our API
The FRONTEND
ok its little bit tricky since we already know bolt.new lets just copy our swagger to bolt.new and ask for beautiful interface
and this is the prompt that i use on bolt.new
create me a nextjs 14 app with tailwind css
this app is for upload candidate and search candidate
that have 3 menu
add candidate from text
add candidate uploading pdf resume
search/query candidate
all of this will hit API on localhost:8000
with this documentation
{"openapi":"..from swagger...}
From bolt.new and little bit tweak like cors, fix some dependencies. and this is the result.
the frontend is ready, its just took ~6 min to make the frontend app work in npm run dev mode
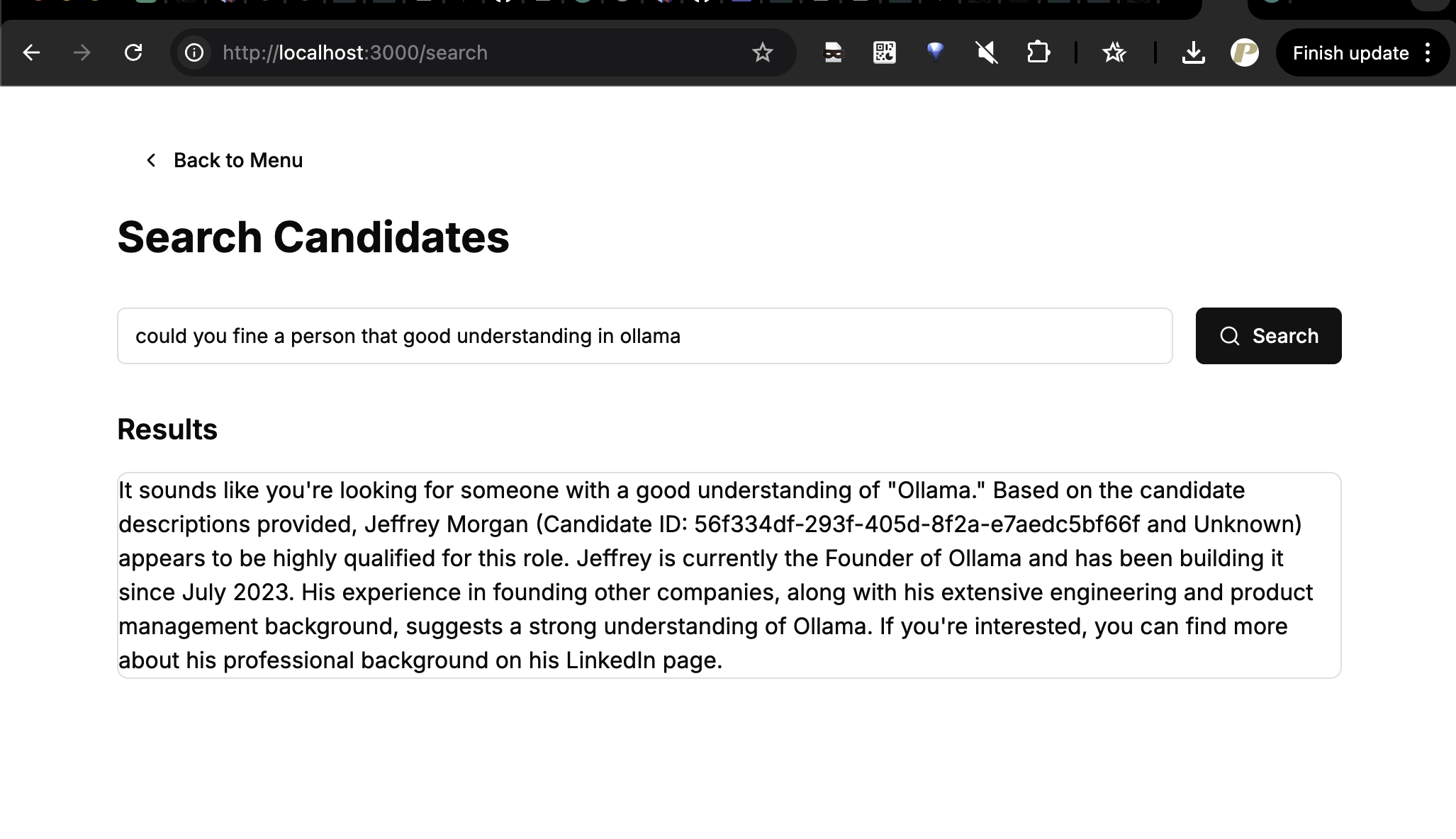
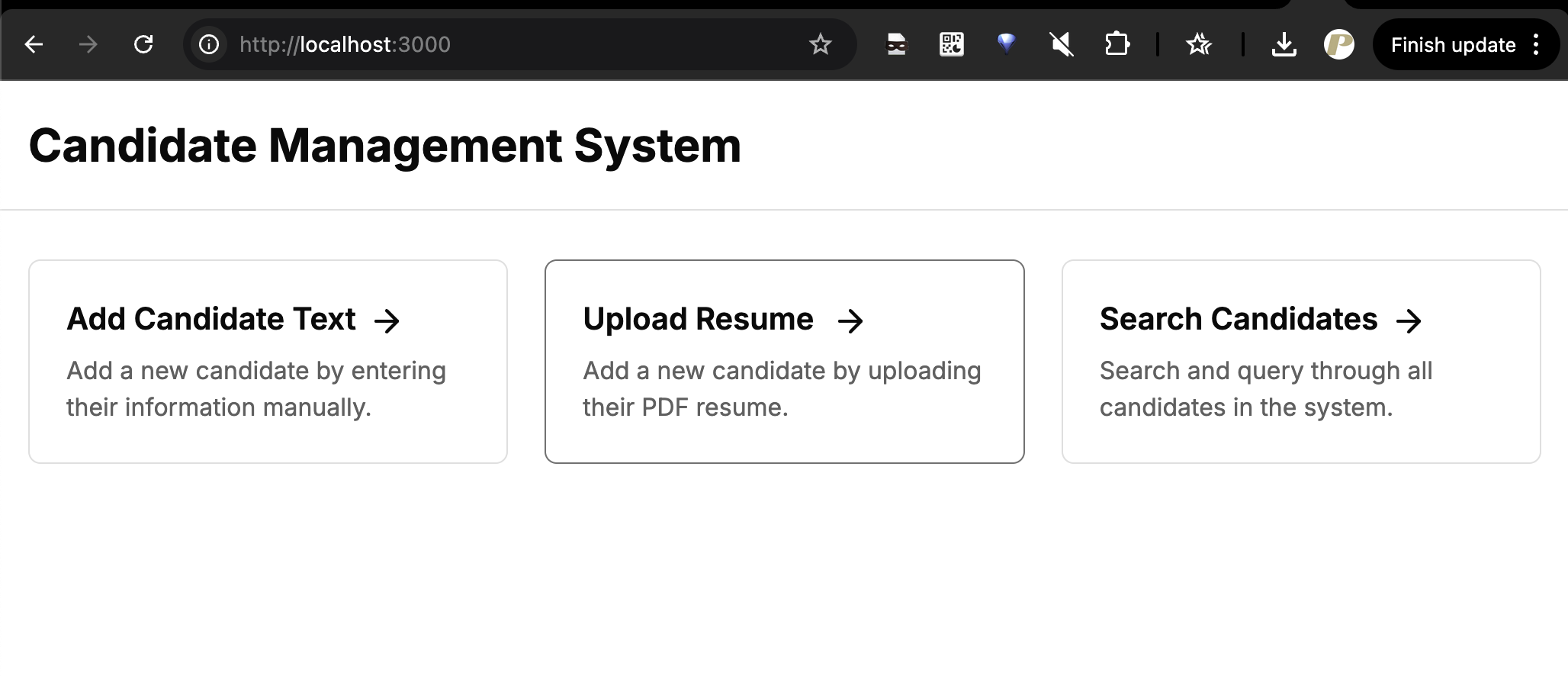
for all the code we could get from this github/prima101112/hirivia need tweak maybe ask there and will try to answer.
Conclusion
In this example we already learn about the RAG on multiple documents, and talk about it. and apply it to simple usecase to searching candidates. so if we have a lot of candidates and need to search the bast candidate or Applicant base on our requirements. this is will help us a lot.